面对网页有道翻译10万字超长文章分段翻译的需求,一次性丢给工具处理往往不现实。超长文本容易触发字数限制、加载延迟与格式错乱,分段策略能把风险降到可控范围,同时维持译文的连贯与一致。做法并非单纯地“切块粘贴”,而是以结构为核心的流程化处理,让机器输出与后期校对相互配合。
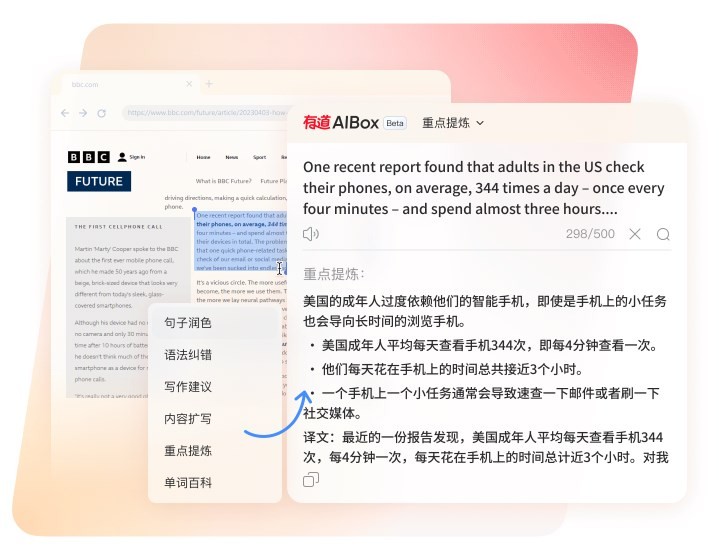
开工前先勘查原文的章节层级,标注标题、副标题、图表说明、脚注与引用块,估算每段的字数区间,建议以完整段落为单位,控制在可稳定处理的上限内,避免切断一句话的中段。准备一个索引表,记录每段起止位置,配套建立术语表与译名清单,把人名、地名、机构、缩写的约定写清楚,顺带统一标点、数字书写和引号样式,以免后期反复修改。
进入操作阶段时,把每一段放入网页翻译页面,得到结果后立即保存到本地文件,用编号命名,写明来源段落与时间戳。为保持上下文的衔接,在下一段开始前可加入上一段结尾的两三句作为提示,减少句际跳跃造成的歧义。遇到超长复合句,宜在自然停顿点断开,保留连接词与指代,降低误译概率。
特殊内容需要额外处理。表格、代码、公式与内嵌引用可用占位符隔离,翻译后再回填原结构;图片中的文字先提取为独立文本,避免在工具内混入无效标记。跨段编号与脚注要保留原序,合并时统一风格,防止注释跑位。对术语的把关不能完全交由机器,先由人工确定基准译法,出现偏差即记录并全局统一。
质量复查采用分批循环:每处理完若干段,进行对照阅读,检查漏译、错位、符号变形与临近句的逻辑顺序;抽样回看原文,验证关键名词与术语是否保持一致,必要时微调断句边界,减少后续整合的摩擦。长时间会话可能出现限流与超时,分批操作能分散负载;一旦浏览器异常,凭编号与索引即可恢复现场,不必从头重来。
合并阶段将所有译段按目录顺序拼接,恢复标题层级与脚注编号,对跨段引用补齐出处,让读者从头到尾拥有平滑的阅读体验。文体方面,技术类文本重在术语精确与逻辑清晰,叙述类文本注重语气与节奏,避免机械直译带来的僵硬;在不改变事实的前提下适度调整词序,使长文更自然。数字单位、时间格式、度量衡与货币符号统一成套规则;人名与缩写在首次出现时确定写法,后续保持不变。
进度管理也很关键,设立里程碑与清单,每完成一章就更新状态,标注难点与决策,后续遇到相同结构可复用经验,积累越多越稳。全部段落合并并通过复审后,再进行二次润色,消除重复与冗余,调整段落长度与过渡语句,让超长文本在目标语言里既完整又易读。借助有道翻译处理分段的主体工作,配合规范化的术语与版式控制,能够以可预期的成本把庞大内容稳妥落地。

